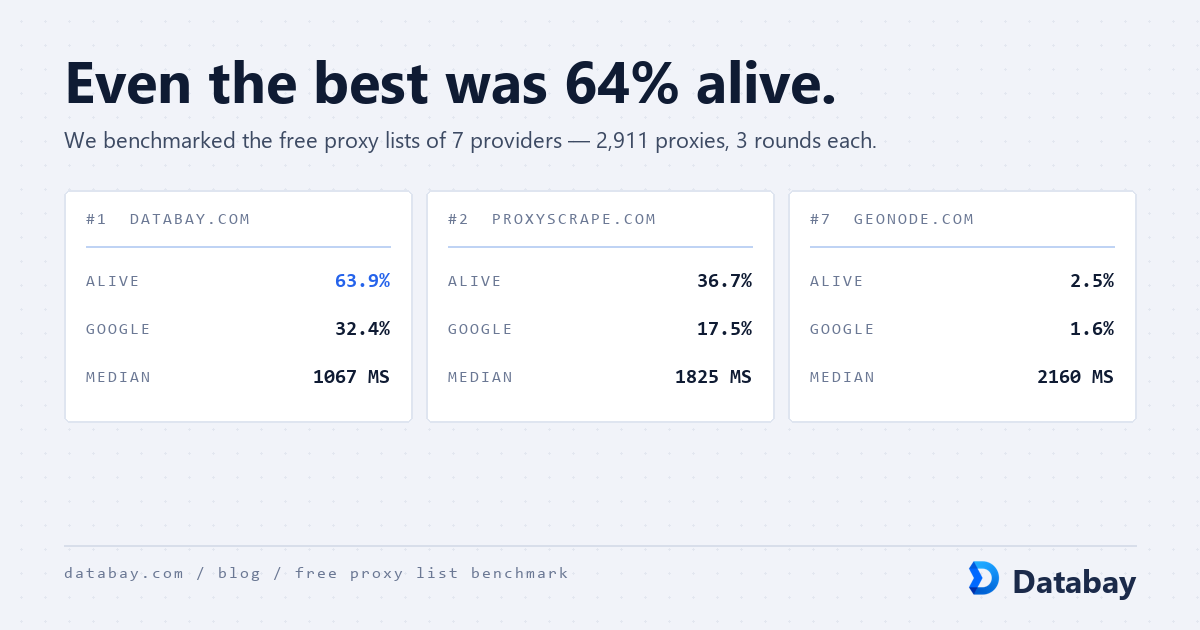
Learn web scraping with proxies from setup to scale. Covers proxy types, tool integration, CAPTCHA handling, session management, and cost optimization.
Why Proxies Are Non-Negotiable for Web Scraping
Every serious scraping operation hits the same wall within minutes: IP-based rate limiting. Websites track incoming requests by IP address, and once you cross a threshold, often as low as 20-30 requests per minute on protected sites, your IP gets flagged, throttled, or outright banned. This is where web scraping with proxies becomes essential rather than optional.
The problem compounds across three dimensions. First, rate limits restrict how many requests a single IP can make in a given window. Second, geographic restrictions block entire IP ranges from accessing region-locked content. Try scraping a European e-commerce site from a US datacenter IP, and you'll get redirected or blocked. Third, anti-bot systems like Cloudflare and Akamai fingerprint connections, and a single IP hammering a site is the most obvious bot signature there is.
Proxies solve all three problems at once. By routing requests through a pool of IP addresses, each individual IP stays well under detection thresholds. Residential proxies add legitimacy because they originate from real ISP-assigned addresses. Geographic targeting lets you access localised content as if browsing from that country. The maths is simple: if a site allows 30 requests per minute per IP and you need 10,000 requests per hour, you need a rotating pool of at least 20 proxies to stay under the radar, and realistically more, because you want headroom.
Choosing the Right Proxy Type for Your Scraping Target
Not all proxies perform equally against all targets. The right choice depends on what you're scraping and how aggressively the site defends itself. Understanding this match-up is the single biggest factor in scraping success rates.
- Residential proxies are the gold standard for scraping protected websites. These IPs belong to real devices on real ISP networks, which makes them nearly indistinguishable from genuine users. Use residential proxies when scraping sites behind Cloudflare, Akamai, or PerimeterX protection: e-commerce platforms, social media sites, travel aggregators, and real estate listings. The tradeoff is cost: residential bandwidth is more expensive per gigabyte.
- Datacenter proxies work well for targets with lighter protection: APIs, public data portals, government databases, news archives, and academic sources. They offer faster speeds and lower costs per request. Many scraping operations use datacenter proxies as their primary workhorse for 70-80% of targets that do not employ aggressive bot detection.
- Mobile proxies carry the highest trust scores because they use genuine 5G/4G mobile network IPs. These IPs are shared among thousands of real mobile users via CGNAT, so blocking them risks blocking legitimate traffic. Reserve mobile proxies for the hardest targets: platforms with the strictest anti-bot measures where residential proxies still get flagged.
A cost-effective strategy uses all three: datacenter proxies for easy targets, residential for protected sites, and mobile proxies only when the other two fail. This tiered approach can reduce proxy costs by 40-60% compared to using residential proxies for everything.
Integrating Proxies with Popular Scraping Tools
The practical mechanics of web scraping with proxies vary by tool. The core pattern is consistent: configure your HTTP client to route requests through a proxy endpoint, handle authentication, and manage rotation.
With Python's requests library, proxy integration is a configuration step. You pass a proxy dictionary with your HTTP and HTTPS proxy URLs, including authentication credentials. The key consideration is session management. Using a requests.Session object maintains cookies and connection state across requests through the same proxy, which is critical for multi-page scraping workflows like paginated results or login-protected content.
Scrapy, the most widely used Python scraping framework, supports proxies through middleware. You configure a custom downloader middleware that assigns proxy addresses to each request. Scrapy's architecture makes it natural to implement rotation logic. Your middleware can pull from a proxy pool and assign different proxies per request or per domain. The framework's built-in retry middleware pairs well with proxy rotation: on a 403 or 429 response, retry the request through a different proxy.
For JavaScript-heavy sites requiring browser automation, Puppeteer and Playwright both accept proxy configuration at browser launch. The approach differs from HTTP-level proxying because the entire browser session, including all asset requests, WebSocket connections, and API calls, routes through the proxy. This is essential for sites that validate consistency between the page request and subsequent resource loads. Playwright's context-based proxy support is particularly useful. You can run multiple browser contexts with different proxies at the same time, enabling parallel scraping of geo-restricted content.
Request Header Management and Fingerprint Consistency
Proxies change your IP address, but sophisticated anti-bot systems look far beyond IP. Your request headers must tell a consistent story that matches your proxy's characteristics. Getting this wrong is one of the most common reasons scrapers get blocked even with high-quality proxies.
User-Agent rotation is the baseline. Maintain a list of current, real User-Agent strings from actual browsers, Chrome, Firefox, Safari, Edge, and rotate them across requests. The critical rule: once you assign a User-Agent to a session, keep it consistent for the duration of that session. Switching User-Agents mid-session is a strong bot signal.
Accept-Language headers should match your proxy's geographic location. If you're routing through a German residential proxy, your Accept-Language should include "de-DE" as a primary language. A request arriving from a German IP with "en-US" as the sole Accept-Language header is technically valid but statistically unusual, and anti-bot systems flag statistical anomalies.
Beyond individual headers, consider the overall fingerprint. HTTP/2 settings, TLS cipher suite ordering, and header ordering all contribute to a connection fingerprint. Modern anti-bot systems like Akamai Bot Manager create a hash of these attributes. When your fingerprint does not match any known browser, the request gets flagged. Tools like curl-impersonate and specialised libraries exist specifically to replicate genuine browser fingerprints at the TLS and HTTP/2 level.
Handling CAPTCHAs and JavaScript Challenges
CAPTCHAs and JavaScript challenges are the escalation response when passive detection flags a request as suspicious. The best strategy is to avoid triggering them in the first place. Proper proxy rotation, realistic headers, and human-like request patterns keep most sessions CAPTCHA-free. When challenges do appear, you need a plan.
JavaScript challenges, like Cloudflare's "Checking your browser" interstitial, require a real browser environment to solve. Headless browsers handle these automatically because they execute JavaScript natively. The challenge generates a token after running computational checks, and subsequent requests using that token pass without further challenges. This is where session persistence matters. Capture the challenge token and associated cookies, then reuse them for follow-up requests through the same proxy IP.
For visual CAPTCHAs (image selection, text recognition), the options are CAPTCHA-solving services that use human workers or AI models, or simply discarding the blocked request and retrying through a fresh proxy. The retry approach works well with large proxy pools. If only 2-5% of requests trigger CAPTCHAs, it's more cost-effective to rotate to a new IP than to solve each CAPTCHA.
The emerging challenge in 2026 is behavioural analysis. Systems like PerimeterX track mouse movements, scroll patterns, and interaction timing. When scraping sites with behavioural analysis, headless browsers need to simulate realistic user interactions, random scroll depths, variable time-on-page, and natural mouse trajectories, before extracting data.
Ethical Scraping: robots.txt and Rate Limiting
Responsible web scraping with proxies means respecting the boundaries site operators set, even when you technically have the capability to bypass them. This is not just ethical. It's practical. Sites that detect aggressive, boundary-ignoring scrapers invest more in anti-bot measures, making everyone's job harder.
Always check robots.txt before scraping a new domain. This file specifies which paths are off-limits to automated access and often includes a Crawl-delay directive indicating the minimum interval between requests. A robots.txt entry of "Crawl-delay: 10" means the site operator asks for at least 10 seconds between requests from a single bot. Honour this even when using proxies. The intent is to limit server load, and distributing rapid-fire requests across proxies while ignoring Crawl-delay technically complies with the letter but violates the spirit.
Set realistic rate limits per domain regardless of your proxy pool size. A good baseline: 1-3 requests per second per domain for moderately sized sites, scaling down to 1 request every 2-5 seconds for smaller sites with limited server capacity. For large platforms like major e-commerce or social media sites, you can often sustain higher rates because they have the infrastructure to handle it. But monitor for 429 responses and back off immediately when they appear.
Keep records of your scraping activity. Log which domains you scrape, at what rates, and whether you encountered any resistance. This documentation protects you if questions arise about your scraping practices and helps you optimise your approach over time.
Session Management for Multi-Page Scraping
Many scraping workflows require keeping state across multiple pages: logging in, navigating search results, following pagination, or building a shopping cart to extract dynamic pricing. Session management determines whether these workflows succeed or fail.
The core principle is session-proxy affinity: bind a browsing session to a specific proxy IP for its entire duration. If you log into a website through one IP and then make the next request through a different IP, the session cookie becomes invalid at best, and the account gets flagged at worst. Sticky sessions, where the proxy provider routes all requests with the same session identifier through the same IP, solve this cleanly.
Cookie handling requires attention to detail. Capture all Set-Cookie headers from responses and replay them in subsequent requests. Pay particular attention to cookies set by anti-bot JavaScript. These often contain validation tokens that must persist across the session. When using headless browsers, the browser handles cookies automatically, which is one reason browser-based scraping succeeds on sites where raw HTTP requests fail.
For paginated scraping, maintain a logical separation between the discovery phase (collecting all page URLs) and the extraction phase (scraping each page). During discovery, you can use rotating proxies because each request is independent. During extraction, use sticky sessions if the pages require authentication or if the site serves different content to returning versus new visitors. This hybrid approach maximises both speed and reliability.
Error Handling and Retry Logic
Solid error handling separates production-grade scrapers from scripts that break overnight. When running web scraping with proxies at scale, expect a baseline failure rate of 2-10% depending on target difficulty, and build your system to handle it gracefully.
HTTP 403 (Forbidden) typically means the proxy IP has been detected and blocked. The correct response: retire that proxy for this domain, switch to a different IP, and retry the request. Do not retry the same proxy. Once blocked, an IP stays blocked for hours or days. HTTP 429 (Too Many Requests) signals rate limiting. Back off exponentially: wait 5 seconds, then 15, then 45. If you get 429s consistently, reduce your overall request rate for that domain.
Connection timeouts and HTTP 503 errors usually indicate server-side load issues rather than bot detection. Retry these with the same proxy after a short delay. Network-level errors like connection resets can indicate proxy issues: the proxy server itself is overloaded or the IP has been blocked at the network level.
Implement a dead proxy detector that tracks success rates per proxy IP. If a proxy's success rate drops below 80% over its last 20 requests, pull it from rotation temporarily. Proxy providers like Databay handle much of this automatically through their rotation infrastructure, but your application-level monitoring adds a second layer of resilience. Log every failed request with its status code, proxy IP, target URL, and timestamp. This data is invaluable for diagnosing systemic issues.
Scaling from Hundreds to Millions of Requests
The architecture that works for 500 requests per day collapses at 500,000. Scaling web scraping with proxies requires rethinking your approach across infrastructure, proxy management, and data pipeline design.
At the infrastructure level, move from single-threaded sequential scraping to an asynchronous, distributed system. A queue-based architecture works well: a scheduler populates a task queue with URLs to scrape, worker processes pull tasks from the queue and execute them through the proxy pool, and results flow into a separate storage pipeline. This decouples scraping speed from data processing speed and lets you scale workers independently.
Proxy pool management becomes critical at scale. You need enough unique IPs to distribute load without burning through proxies faster than they recover. A practical formula: for N requests per hour with a per-IP limit of R requests per hour per domain, you need at least N/R unique IPs per target domain, plus a 50% buffer for IPs in cooldown. At millions of requests per day, this typically means pools of 10,000+ residential IPs.
Data storage strategy matters too. Writing scraped data directly to a database creates a bottleneck. Instead, write raw responses to fast storage (local disk or object storage), then process and structure the data in a separate pipeline. This lets you re-parse data without re-scraping if your extraction logic changes, and it prevents database slowdowns from blocking your scraping throughput.
Monitor everything: requests per second, success rates per domain, proxy utilisation, queue depth, and data volume. Set alerts for success rate drops. A sudden decrease usually means the target site has changed its structure or upgraded its bot detection.
Cost Optimization: Mixing Proxy Types Strategically
Proxy costs can dominate the budget of a large-scale scraping operation. The key insight is that not every request needs the most expensive proxy type. A tiered strategy based on target difficulty slashes costs without sacrificing success rates.
Start by categorising your target sites into difficulty tiers. Tier 1 (easy) includes public APIs, government data portals, and sites with no bot detection, use datacenter proxies, the cheapest option. Tier 2 (moderate) covers sites with basic bot detection like simple rate limiting and header checks, datacenter proxies with proper rotation and headers work here. Tier 3 (hard) includes sites behind Cloudflare, Akamai, or similar WAFs, use residential proxies. Tier 4 (hardest) covers sites with advanced behavioural analysis and aggressive blocking, reserve mobile proxies for these.
In practice, most scraping workloads follow an 80/20 pattern: 80% of targets fall into Tiers 1-2, and only 20% require residential or mobile proxies. By routing each request to the appropriate proxy tier, you can reduce costs by 50-70% compared to using residential proxies universally.
Bandwidth optimisation adds another cost lever. Disable image and media loading when using headless browsers. This alone can cut bandwidth by 60-80%. Strip unnecessary headers from requests. Compress responses where possible. For monitoring or change-detection use cases, use conditional requests (If-Modified-Since, If-None-Match) to avoid downloading pages that have not changed since your last scrape. These techniques compound: a 50% reduction in bandwidth cost plus a 50% reduction in proxy tier cost yields 75% total savings.
Common Mistakes That Get Scrapers Blocked
Even experienced developers make mistakes that lead to detection and blocking. Recognising these patterns helps you avoid them.
- Sequential URL patterns. Scraping /product/1, /product/2, /product/3 in numeric order is an unmistakable bot signature. Randomise your URL order and add variable delays between requests.
- Ignoring response content. Some sites serve honeypot pages: normal-looking HTML with hidden links or invisible form fields that only bots interact with. Parse response content and skip links or fields marked with display:none or visibility:hidden.
- Identical timing intervals. Making requests exactly every 2.0 seconds is mechanical. Add jitter: randomise delays between 1.5 and 3.5 seconds to simulate human browsing variance.
- Skipping the homepage. Real users rarely navigate directly to deep pages. Start sessions by loading the homepage or a category page, then navigate to target pages. This establishes a natural referrer chain.
- Ignoring Set-Cookie headers. Many anti-bot systems use tracking cookies to build a behavioural profile. Discarding cookies forces the site to treat every request as a new visitor, which is itself a suspicious pattern.
- Using outdated User-Agent strings. A Chrome 95 User-Agent in 2026 stands out. Update your User-Agent pool regularly to reflect current browser versions.
Building a Production Scraping Pipeline
A production-grade scraping system is more than a script with proxies attached. It's a pipeline with distinct stages, each handling a specific responsibility, designed to run continuously with minimal manual intervention.
The pipeline starts with a URL manager that maintains the list of targets, tracks which URLs have been scraped and when, and schedules re-scraping based on content change frequency. High-change targets (news sites, stock prices) might need hourly scraping; stable targets (company directories, historical records) might need monthly checks.
The request layer handles proxy selection, header assembly, and retry logic. This layer should be stateless. It receives a URL and configuration, makes the request through the appropriate proxy, and returns the raw response. Keeping it stateless makes horizontal scaling trivial: just add more worker instances.
The parsing layer transforms raw HTML into structured data. Separate your parsing logic from your scraping logic so you can re-parse stored responses without re-scraping. Use CSS selectors or XPath for HTML extraction, and always build in validation: check that extracted prices are numeric, dates parse correctly, and required fields are present.
Finally, the storage and delivery layer loads structured data into your database, data warehouse, or API. Include deduplication at this stage: if the same product was scraped from multiple pages, merge the records. Quality monitoring, comparing today's data volume and distribution against historical baselines, catches extraction failures before they corrupt your dataset. This end-to-end architecture turns web scraping with proxies from a fragile script into a reliable data infrastructure.